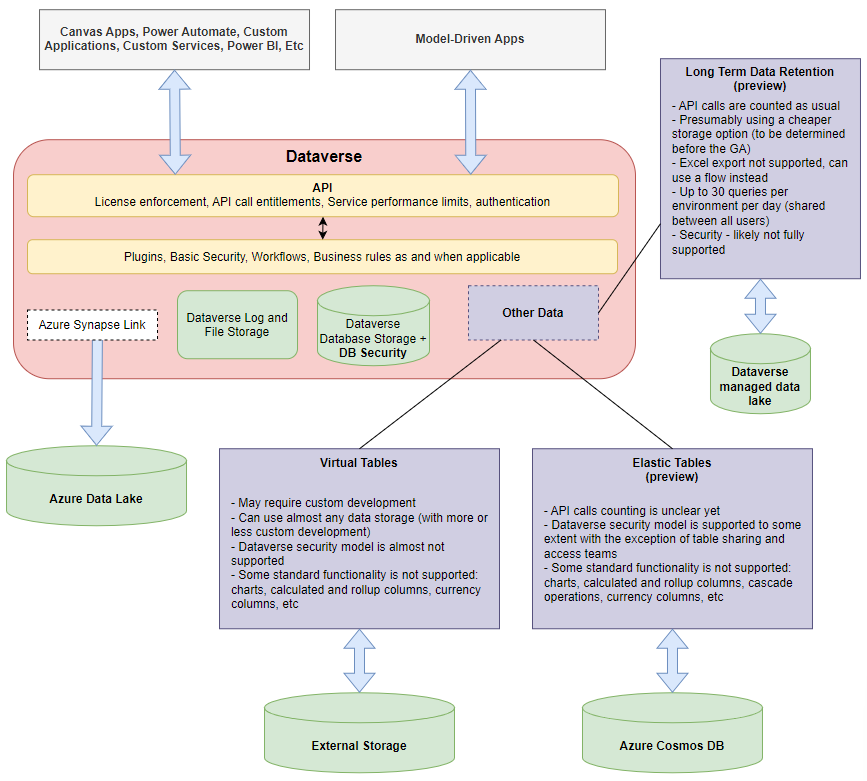
I was trying to visualize Dataverse data storage options, and this is where the diagram below started, but it actually did not go quite as planned and ended up being something slightly different. It seems difficult to look at the data options out of the context, so that’s the reason I had to keep adding those other pieces as well:
There seem to be no way to come up with a short definition of what Dataverse is. It is a service, yes, but that’s not saying anything about what that service is.
I actually think Microsoft might also do better providing those definitions, since, if you look at the page below:
https://learn.microsoft.com/en-us/power-apps/maker/data-platform/data-platform-intro
You’ll see that it’s talking about how we can create tables, manage data, add security, etc. But this is mostly relevant for the Dataverse Database storage, and it’s much less relevant for the Virtual Tables, Elastic Tables, yet it completely leaves API out of the picture, though API is not there just to pass through incoming requests to the data layer – it’s also there to enforce licensing, some security, various entitlement and service performance limits, etc.
Which sometimes leads to the situations where someone would be talking about Dataverse database as if it were just another database, but it’s not. To put it simple, there is just no access to the database to start with, there is only access to the API-s (unless we are talking about some of the external options, such as Virtual Tables).
Which, interestingly enough, brings me to the actual question. Is the value of Dataverse somewhat artificially inflated? Would Dataverse still have any value if that API layer were replaced, somehow, to pass through all incoming requests to the SQL database (“hello on-prem, how are you doing these days”).
I know where it literally does have value – part of the role those API-s are playing is to enforce proper licensing, limits, and ensure service performance so that we all knew what kind of licenses we need to purchase. Which is important, of course, but only the service performance part is important to the Dataverse consumers, whereas the rest is mostly needed to clarify all the confusions caused by this licensing model when the counters/stats are not properly surfaced.
Either way, the answer is a bit two-fold, it seems. There is no license which would give us access to Dataverse only. There are Power Apps licenses, there are Power Automate licenses, there are M365 licenses, etc. They are all there to let us use some other features, and Dataverse is, normally, just a part of the overall licensing package. It’s like a backbone for everything else – first party applications are using it to store data, model-driven applications are using it for the same purpose, there are lots of out of the box tables in Dataverse which are there to support all sorts of functions (approvals, for instance). So it definitely does have value in that sense, but is it because Microsoft decided to turn it into the backbone for its own applications, ALM, etc, or is it because this was, actually, the best option to go with (as in, what if it were Azure SQL?) I guess right now it’s almost impossible to say, since it all started way back, and it just kept evolving.
And, yet, if I were to call out a single problem with Dataverse that gets me just about all the time, it’s limits and licensing, which is now going to be a problem for the whole of Power Platform, too, since, even when not using Dataverse, all connector requests will be counted. Dataverse is somewhat worse in that sense, though. I can send a single query to SQL to update millions of records in almost no time, but I can’t do the same in Dataverse – instead have to do it one record after another, and those calls are counted separately, not to mention that this does not perform nearly as well as native SQL.
Well, I wish Microsoft were looking into how to, perhaps, give us direct access to the database? Which is risky, of course, because of the data integrity et all, but that would make things so much easier to do sometimes.
Instead, I keep running into more and more limits all around – the latest one is that there can be only 30 queries per day per environment (not per user) when working with the retained/archived data, and that’s where this kind of posts get born.