There are all sorts of definitions of what Microsoft Dataverse is. Just go to https://powerplatform.microsoft.com/en-us/dataverse/, and you’ll get a few right away:
Microsoft Dataverse is the data backbone that enables people to store their data in a scalable and secure environment dynamically. It enables [us] to look at data as a service spun up on-demand to meet ever-changing business needs.
Microsoft Dataverse allows my team to provide business value faster through low-code solutions while still having pro-code as a safety net for more complex requirements.
Getting security and compliance right across many services is hard. [Microsoft Dataverse] gives me one security and auditing model.
And the one below comes from the training module:
Microsoft Dataverse is a cloud-based solution that easily structures various data and business logic to support interconnected applications and processes in a secure and compliant manner.
However, even though it may look, sometimes, as if Power Platform and Dataverse were inseparable, but they are. One can build a Canvas App without using Dataverse at all, yet far not every Power Automate flow will be connecting to Dataverse. But, of course, Model-Driven apps do need it.
Microsoft Dataverse serves multiple purposes in the Power Platform world – it’s a service used by Microsoft to deliver some of the Power Platform functionality such as solution-based ALM. It’s also a data management service that’s used for a number of first-party solutions such as Customer Service, Sales, Mareting, etc. But it’s also a data management solution that application developers can user to store their data when developing with Power Platform, and it’s the only data management option that works for Model-Driven apps.
Still, why don’t we just call it a database?
Well, there are multiple examples where it behaves differently from what you’d be expecting from your usual database – sometimes it’s useful, and, sometimes, it’s challenging.
As a service, it offers (among other things):
- Custom security model that goes beyond the regular CRUD
- Server-Side extensibility (plugins)
- Custom column types (lookups, optionsets)
- Custom column formats for the regular data types (such as the ability to define whether a datetime field is going to be timezone independent or not)
- It scales automatically
It also offers some additional out of the box features and perks such as custom data modelling UI, duplicate detections jobs and related UI, scheduled system jobs, and more. But I’d argue that almost every database out there is offering those, too.
Note: I guess FetchXML, as a proprietary query language, needs to be mentioned, too. It makes things more complicated, and the sole reason for its existence is, likely, the fact that all that security and custom data types are not “natively” supported in SQL.
What Microsoft Dataverse does not offer, and to a large extent it’s probably because it has to ensure it can keep offering what I listed above, is direct write access to the Database. There is an option to use TDS endpoint for read operations, though it’s questionable how useful it is outside of the Power BI reporting scenarios, but there is no option to write directly into the database – everything has to go through the API-s.
Which is where, I think, the main problem of any Dataverse-based solution is. The fact that we have to use custom API rather than native SQL, brings with it a couple of limitations:
- From the licensing perspective, those API calls are relatively expensive. They are definitely more expensive (on any large implementation) than SQL calls, and, even though Dataverse scales automatically, you don’t necessarily even need it to scale since you may not want to get to those levels of utilization. Depending on how you count, you will be hovering at around $0.0002 per API call at least, so, if you ever have to do a mass update to fix the data, that will cost you over $20 per 100K records, and, then, if you have to do it daily, yet if you have multiple users, yet if your application is heavy on the API usage, this will all be adding up. Although, the initial usage is covered through license entitlements, but it’s all adding up fast.
- From the usability perspective, if you ever had to update hundreds of thousands of records through the API, you may have noticed it’s a relatively slow process and it may take anywhere from a few hours to a few days, whereas doing the same kind of update directly in SQL will normally take only a few minutes.
Personally, I have yet to find a large project (as in, at least 500K records… which is not large in reality) where I would not have to work around the API slowness by allowing more time for data migration, for instance (not just for the actual run, but, also, for the initial development / testing), and, lately, by having to watch out for the request limits.
Which is why the architecture below usually works better with Dataverse:
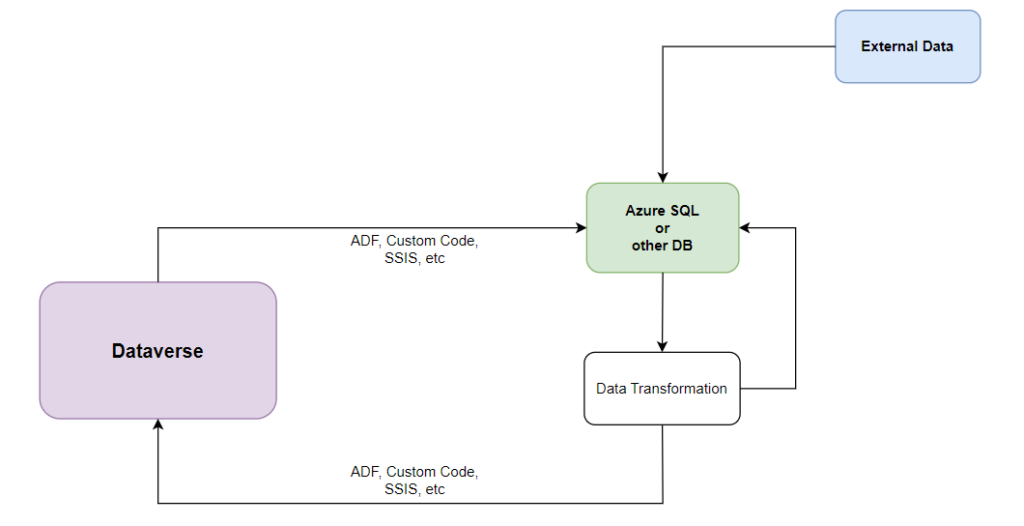
But, of course, since it’s more complicated to set up than having everything stored and done directly in Dataverse, we often and up with “let’s do everything in Dataverse directly”, and, then, we pay the price literally and figuratively by having to purchase additional licenses and/or by having to spend more time debugging and/or just waiting for the ETL jobs to complete.
I am not sure if Microsoft is ever going to be able to open up Dataverse database so that we’d be able to use SQL there (instead of having to go through the API) – that would be awesome, and, perhaps, would allow for the utilization-based billing to show up which would be on par with Azure SQL.