Integrating external data with model-driven applications in the Microsoft Dataverse can be a challenging task for a number of reasons:
- Data volumes
- Storage costs
- API throttling and entitlement limits
- Technology limitations
- Lack of experience with the tools/technologies
- Vague requirements where a little change can affect the whole approach to the integration
In this post, I just wanted to provide a high-level overview of how this could be looked at, and, also, a few references to the Microsoft documentation which might be useful in this context.
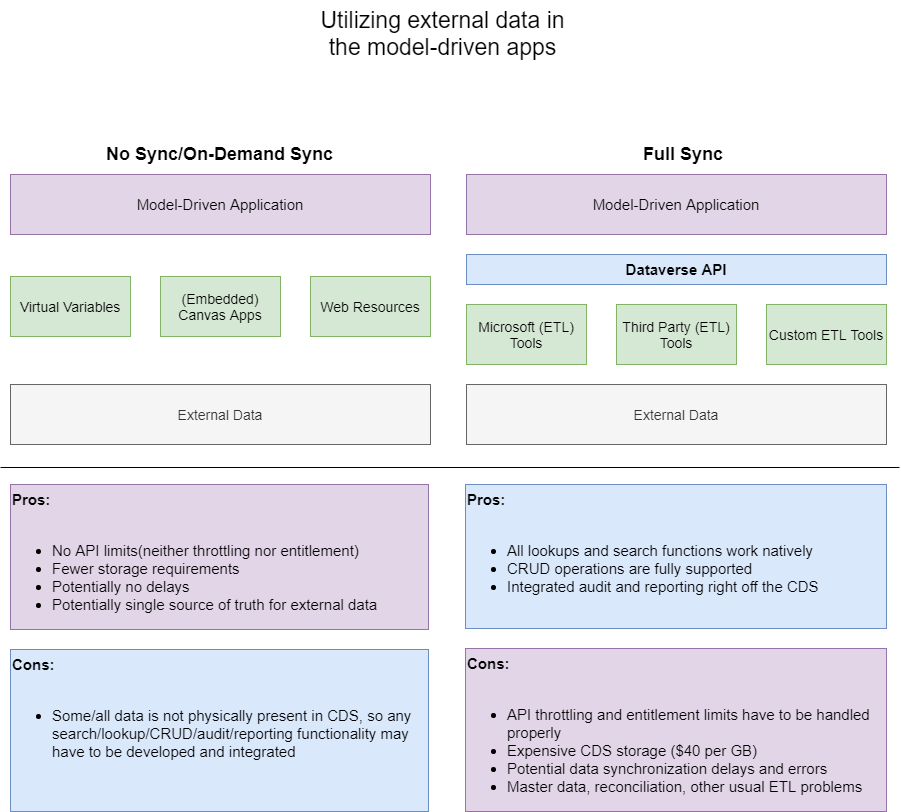
Basically, it seems there are two options:
- We can load data into Dataverse and deal with the ongoing data integration
- Or we can try integrating external data without actually storing any/most of it in the Dataverse
There are a few major challenges with the “full sync” approach:
- API limits (throttling and entitlement). This is because we can’t get around that API layer on the diagram
- Storage costs and capacity model
- Having to create and maintain those ETL jobs
For the API limits, have a look here: Requests limits and allocations
For the capacity model, here is another link: New Microsoft Dataverse storage capacity
For the storage costs, here is a link: Latest Customer Engagement Licensing Change Could Lead to Dynamics 365 Storage Cost Increase
As for the technology limitations, there can be a bunch of problems:
- MFA support
- Ability to handle API throttling gracefully
- Ability to run under application accounts
- Ability to “rotate” user accounts (to work around those throttling limits)
- Data protection (will your data be stored somewhere other than in the Microsoft cloud?)
- And probably a lot more…
Lack of experience in the team can hit you badly, really. You can go with one ETL tool since it seems to be suitable, and, then, you’ll realize half-way through the project that something is missing. If only you knew from the beginning…
And this is where, once everything has been lined up and you are moving forward with the integration, a small change in the requirements can bring you back to where you started. Because, what if you were assuming you don’t have to do full sync and, suddenly, you have to do it? You might start hitting those thresholds, you may have to find a better tool, you may have to train the team, etc.
And, as for the “partial sync” or “no sync”, the biggest challenge there is that you do have to tread very carefully.
Virtual entities might give your integration the most “natural” feeling, since you’ll be able to show them in the views, you’ll be able to use them in the lookups, and you’ll be able to use familiar model-driven forms (I’m still looking to do a few more posts on that topic, but have a look here for what I have so far). There will be limitations, though, since those are “virtual” entities, not the real ones. So, for example, if you think of building various advanced find views, you might just hit a wall there – essentially, you may have to combine data from two different data sources somehow.
You might use canvas apps, but, even though you can use them to surface data in the model-driven app, that’s just as far as you can go. Using external data in the lookups? No way. Using external data in the advanced find? That would not be an option. Also not an option (with the data not present in Dataverse as at least a virtual entity): excel export, excel import, word templates, etc.
And, yet, the problem of data integration keeps coming over and over – it just seems every case is special, so I’d be curious to here of how do you decide on the approach (for different data volumes etc).
On my side, and based on some of the discussions I was part of, it seems Dataflow can be the way to go for a number of reasons when bringing huge amount of data to Dataverse, so that might be the topic of one of the next posts.